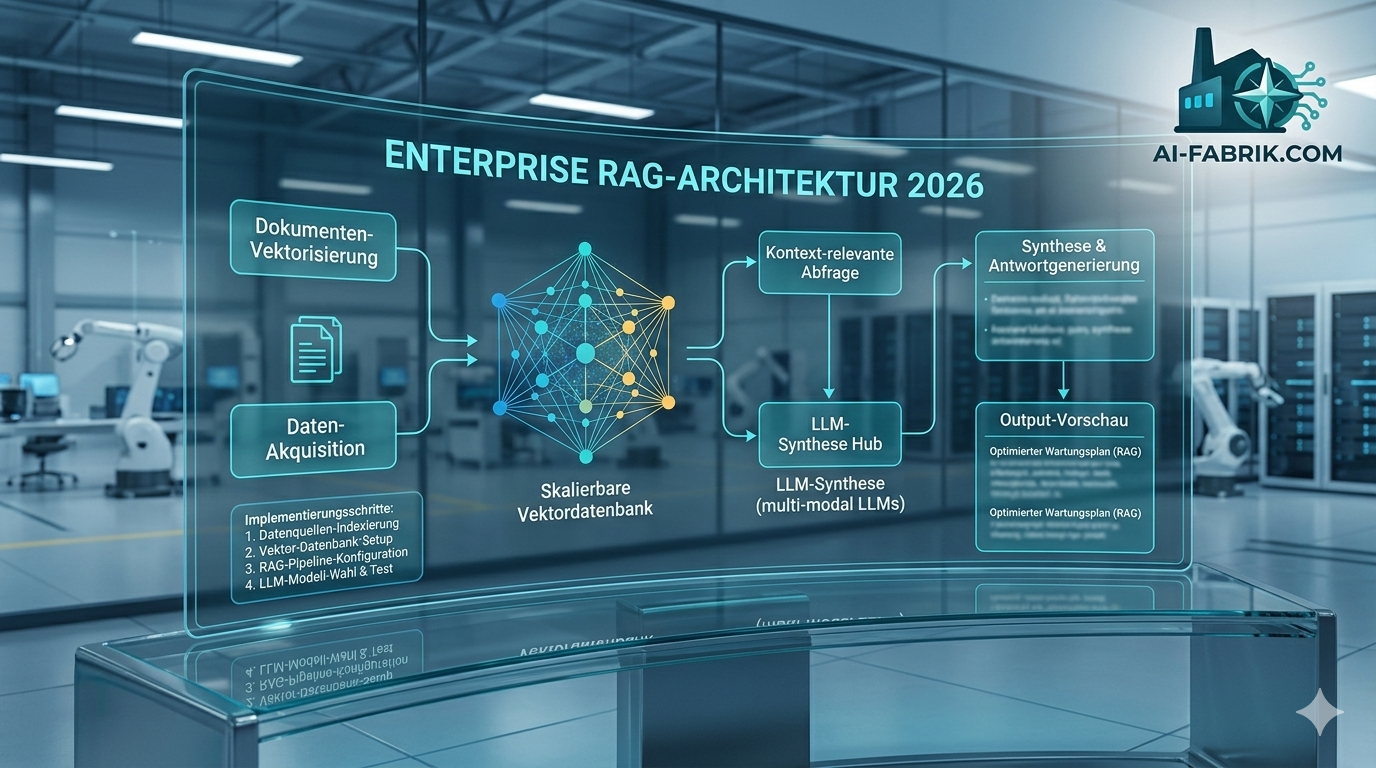
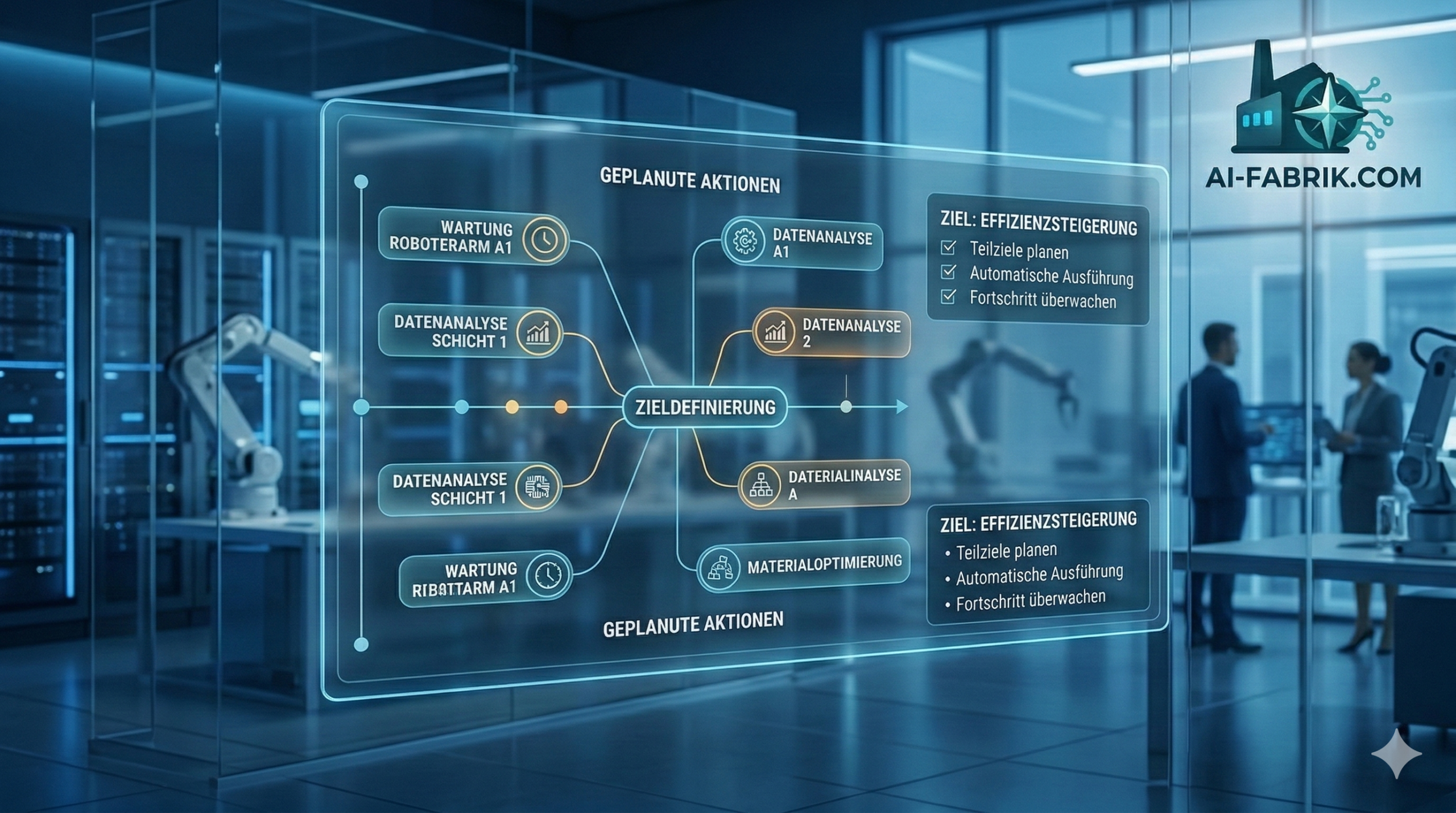
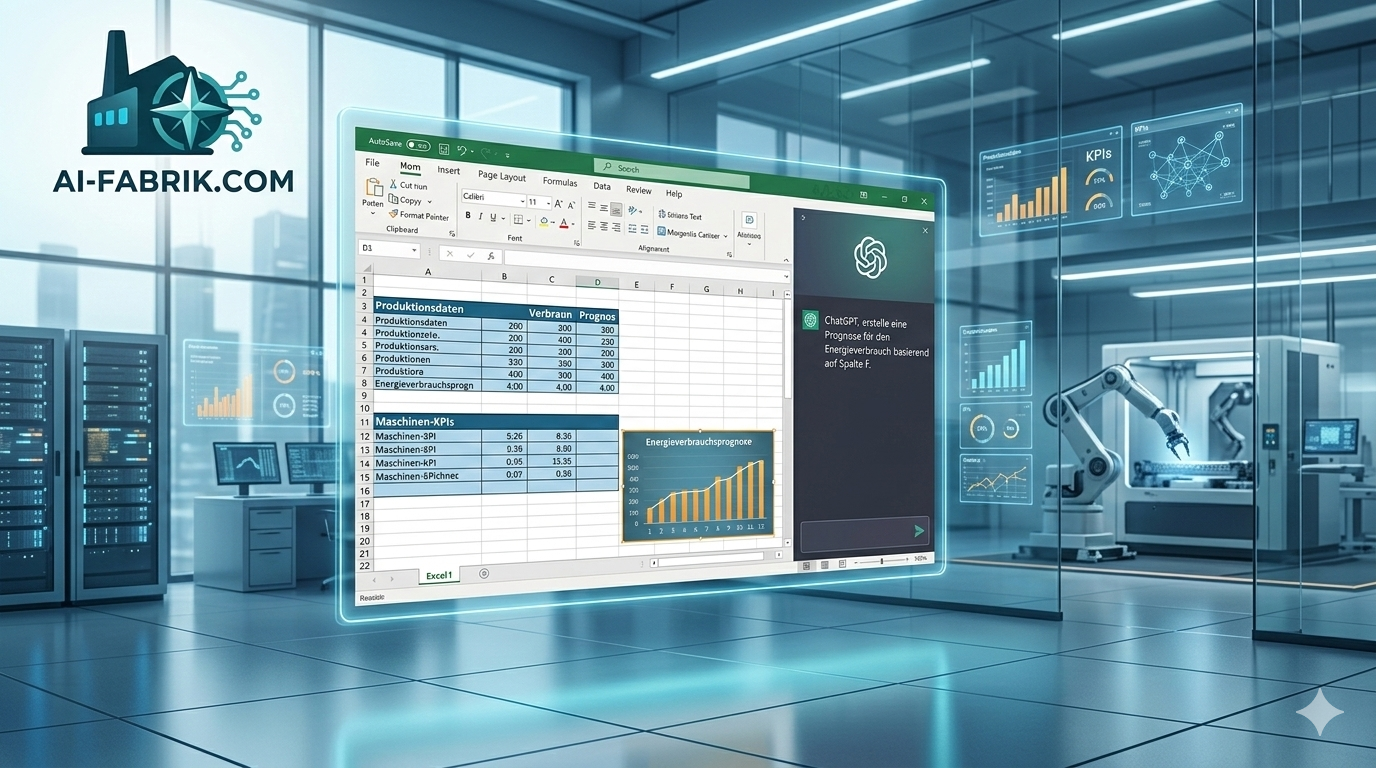
Am 16. Februar 2026 hat das Qwen-Team von Alibaba Cloud die nächste Generation seiner KI-Modellfamilie veröffentlicht: Qwen3.5. Das erste Modell der neuen Serie, Qwen3.5-397B-A17B, ist ab sofort als Open-Source-Modell verfügbar – und markiert einen bemerkenswerten Schritt in der Entwicklung effizienter, leistungsstarker und nativ multimodaler Sprachmodelle. Parallel dazu erscheint mit Qwen3.5-Plus eine gehostete Variante über die Alibaba Cloud Model Studio API.
Was ist Qwen3.5?
Qwen3.5 ist keine bloße Versionsnummer-Erhöhung. Es handelt sich um die erste vollständig nativ multimodale KI-Modellfamilie des Qwen-Teams – also ein Modell, das Text und Bilder nicht nachträglich kombiniert, sondern von Grund auf gemeinsam trainiert wurde. Das Flaggschiff Qwen3.5-397B-A17B verfügt über insgesamt 397 Milliarden Parameter, aktiviert jedoch dank einer sparsamen Mixture-of-Experts (MoE)-Architektur bei jedem Inferenzschritt nur 17 Milliarden Parameter. Das Resultat: maximale Leistung bei minimalem Rechenaufwand.
Alibaba positioniert das Modell explizit als Antwort auf die Anforderungen der sogenannten Agentic AI Era – also KI-Systeme, die eigenständig komplexe, mehrstufige Aufgaben ausführen können, ohne bei jedem Schritt auf menschliche Intervention angewiesen zu sein.
Technische Grundlagen: Architektur und Training
Qwen3.5 baut auf der Architektur des Vorgängers Qwen3-Next auf und kombiniert mehrere technische Innovationen miteinander:
Sparse MoE mit Hybrid-Attention
Die MoE-Architektur ermöglicht es, nur die relevanten „Experten-Subnetze“ zu aktivieren – abhängig von der jeweiligen Anfrage. In Kombination mit einem hybriden Attention-Mechanismus werden damit deutlich schnellere Dekodiergeschwindigkeiten erreicht, ohne Abstriche bei der Qualität hinnehmen zu müssen. Alibaba gibt an, dass das Modell im Vergleich zum Vorgänger eine achtfache Verarbeitungskapazität bei großen Workloads erreicht.
Natives Vision-Language-Training (Early Fusion)
Statt Sprache und Bildverständnis nachträglich zu kombinieren, wurde Qwen3.5 von Anfang an auf Billionen multimodaler Token trainiert. Dieser sogenannte Early-Fusion-Ansatz führt dazu, dass das Modell visuelle und textuelle Informationen auf einer fundamentalen Ebene integriert – und damit bei Aufgaben wie Bild-zu-Text-Analyse, multimodalem Reasoning und visuellen Agenten deutlich stärker abschneidet als Modelle mit späterem Fusion-Ansatz.
Erweiterte Sprachunterstützung
Die Sprachabdeckung wurde massiv ausgebaut: von 119 Sprachen und Dialekten bei Qwen3 auf nun 201 Sprachen und Dialekte. Gleichzeitig wurde der Vokabularumfang auf 250.000 Token erhöht, was effizienteres Encoding und Decoding in vielsprachigen Kontexten ermöglicht – ein wichtiger Faktor für global ausgerichtete Anwendungen.
Technische Spezifikationen im Vergleich
Die folgende Tabelle zeigt die wichtigsten technischen Unterschiede zwischen Qwen3.5-397B-A17B und dem Vorgängermodell Qwen3-Max-Thinking:
| Spezifikation | Qwen3.5-397B-A17B | Qwen3-Max-Thinking |
|---|---|---|
| Gesamtparameter | 397 Milliarden | 1 Billion+ |
| Aktive Parameter pro Token | 17 Milliarden | Nicht veröffentlicht |
| Vokabular | 250.000 Token | 152.000 Token |
| Sprachunterstützung | 201 Sprachen | 119 Sprachen |
| Architektur | Sparse MoE + Hybrid-Attention | Dense MoE |
| Training-Pipeline | Natives FP8 | BF16/FP16 |
| Multimodal | Nativ (Early Fusion) | Nur Text |
| Inferenz-Speedup | 8,6x – 19x schneller | Baseline |
Benchmark-Ergebnisse: Wo steht Qwen3.5?
Alibaba hat das Modell auf einer Reihe anspruchsvoller Benchmarks evaluiert. Die veröffentlichten Ergebnisse zeigen, dass Qwen3.5-397B-A17B mit den derzeit führenden Frontier-Modellen konkurrenzfähig ist – darunter GPT-5.2, Claude Opus 4.5 und Gemini 3 Pro. Alibaba behauptet, auf 80 % aller evaluierten Benchmarks besser abzuschneiden als diese Modelle. Für eine endgültige Einordnung fehlen jedoch noch unabhängige, reproduzierbare Tests: Insbesondere Robustheit unter realen Bedingungen, Halluzinationsrate in Fachdomänen und Safety-Verhalten wurden in den veröffentlichten Zahlen nicht detailliert adressiert. Die nachfolgenden Tabellen zeigen die Eigenangaben Alibabas – sie sind ein Ausgangspunkt für eigene Evaluierungen, aber kein Ersatz dafür.
Reasoning & Mathematik
| Benchmark | Score | Kategorie |
|---|---|---|
| AIME26 | 91,3 | Olympiade-Mathematik |
| GPQA Diamond | 88,4 | Graduate-Level Reasoning |
| MMLU-Pro | 87,8 | Mehrsprachiges Fachwissen |
| MMLU | 88,5 | Allgemeinwissen |
| MathVista | 90,3 | Mathematisches Reasoning |
| MathVision | 88,6 | Visuelles Mathematik-Reasoning |
Coding & Agentic Capabilities
| Benchmark | Score | Kategorie |
|---|---|---|
| LiveCodeBench v6 | 83,6 | Wettbewerbsprogrammierung |
| SWE-bench Verified | 76,4 | Reale Coding-Workflows |
| Terminal-Bench 2 | 52,5 | Agentic Terminal Coding |
| BFCL v4 | 72,9 | Agentic Tool Use |
| BrowseComp | 78,6 | Agentic Websuche |
| IFBench | 76,5 | Instruction Following |
Multimodale Benchmarks
| Benchmark | Score | Kategorie |
|---|---|---|
| MMMU | 85,0 | Multimodales Verständnis |
| MMMU-Pro | 79,0 | Multimodales Verständnis (Profi) |
| OmniDocBench v1.5 | 90,8 | Dokumenten-Analyse |
| MathVista | 90,3 | Visuelles Mathematik-Reasoning |
| Video-MME | 87,5 | Video-Verständnis |
| VITA-Bench | 49,7 | Agentic multimodale Interaktion |
| ERQA | 67,5 | Embodied & Spatial Reasoning |
Reality Check: Was die Zahlen wirklich aussagen
Benchmark-Zahlen erzählen immer nur einen Teil der Geschichte. Zwei der Messwerte sind dabei besonders praxisrelevant: SWE-bench Verified (76,4) simuliert echte GitHub-Issues aus realen Open-Source-Projekten – ein Score in dieser Höhe entspricht dem, was ein erfahrener Entwickler in einem strukturierten Tagesablauf lösen kann. BrowseComp (78,6) prüft, ob ein Modell mehrstufige Webrecherchen eigenständig durchführen kann – ohne die Aufgabe nach jedem Schritt neu erklären zu müssen. Beide Benchmarks sind deshalb als Maßstab aussagekräftiger als reine Mathematik- oder Wissensabfragen.
Wo typischerweise Lücken bleiben: Die veröffentlichten Benchmarks messen weder Safety-Verhalten noch die Neigung zu Halluzinationen in spezialisierten Fachdomänen. Für Enterprise-Einsatz besonders relevant ist außerdem das Thema Guardrails – also integrierte Schutzmechanismen, die verhindern, dass ein Modell in automatisierten Workflows unerwünschte Aktionen ausführt oder sensible Daten preisgibt. Alibaba hat zwar mit Qwen3Guard eine separate Safety-Schicht veröffentlicht, deren Integration in produktive Systeme aber zusätzlichen Aufwand erfordert. Wer Qwen3.5 in regulierten Umgebungen (z. B. Finanzdienstleistungen, Gesundheitswesen) einsetzen möchte, sollte diesen Aspekt in der Evaluierungsphase explizit adressieren.
Qwen3.5-Plus: Die gehostete Variante
Neben dem Open-Weight-Modell bietet Alibaba mit Qwen3.5-Plus eine vollständig verwaltete API-Variante über das Alibaba Cloud Model Studio an. Die folgende Tabelle zeigt die wichtigsten Unterschiede zwischen beiden Varianten:
| Merkmal | Qwen3.5-397B-A17B (Open Weight) | Qwen3.5-Plus (Hosted) |
|---|---|---|
| Lizenz | Apache 2.0 | Proprietär (API-Zugang) |
| Kontextfenster | Bis 256K Token (nativ) | 1 Million Token |
| Tool Use | Manuelle Integration | Eingebaut (adaptiv) |
| Plattform | Self-Hosted / HuggingFace | Alibaba Cloud Model Studio |
| Hardware-Anforderung | 8× H100 GPUs (empfohlen) | Keine (verwalteter Dienst) |
| Kosten (ca.) | Eigene Infrastruktur | ~0,18 $ / 1 Mio. Token |
| Ideal für | Datensouveränität, Fine-Tuning | Langkontext-Workflows, Prototyping |
| API-Kompatibilität | OpenAI / Anthropic SDK | OpenAI / Anthropic SDK |
Agentic AI: Was kann Qwen3.5 eigenständig leisten?
Ein besonderes Merkmal von Qwen3.5 sind seine visuellen Agentenfähigkeiten: Das Modell kann selbstständig mobile und Desktop-Applikationen steuern, visuelle Benutzeroberflächen interpretieren und mehrstufige Aufgaben ohne menschliches Eingreifen abschließen. Das umfasst Aktionen wie das Navigieren in Software-Oberflächen, das Klicken auf Buttons oder das Ausfüllen von Formularen – plattformübergreifend.
Diese Fähigkeit macht Qwen3.5 besonders interessant für Unternehmen, die Prozessautomatisierung ohne aufwendige RPA-Implementierungen anstreben. Die Kombination aus starkem Reasoning, multimodaler Wahrnehmung und Werkzeugnutzung positioniert das Modell als ernstzunehmenden Kandidaten für komplexe Unternehmens-Workflows.
Konkrete Enterprise-Szenarien: Ein besonders relevanter Anwendungsfall ist die Automatisierung von Legacy-Webanwendungen, auf die kein modernes API zugreift – etwa ältere ERP- oder Finanzsysteme, die ausschließlich über eine Browser-Oberfläche bedienbar sind. Qwen3.5 kann hier per Screenshot-Analyse die aktuelle Bildschirmansicht interpretieren, Eingabefelder identifizieren und Formulare eigenständig ausfüllen – ganz ohne Anpassung des Quellsystems. Ein weiteres Szenario ist die Navigation durch SAP-Web-GUIs: Das Modell kann komplexe Transaktionspfade (z. B. Bestellanforderung → Genehmigung → Buchung) eigenständig durchlaufen, Pflichtfelder befüllen und Statusmeldungen interpretieren – auch dann, wenn die Oberfläche nicht für API-Zugriff ausgelegt ist. Konkret denkbar: Ein visueller Agent öffnet eine Rechnung aus einem DMS-System, liest Belegdatum, Betrag und Kostenstelle aus, trägt diese Felder automatisch in das ERP-System ein und startet anschließend den Freigabe-Workflow – ohne klassische RPA-Skripte und ohne menschliches Eingreifen. Für Abteilungen, die täglich repetitive Datenerfassung oder Statusabfragen in solchen Systemen betreiben, eröffnet das eine Automatisierungsschicht, die bisher nur mit erheblichem RPA-Aufwand realisierbar war.
60 % günstigere Inferenzkosten: Was steckt dahinter?
Alibaba gibt an, dass Qwen3.5 im Vergleich zum Vorgänger 60 % günstiger in der Nutzung ist. Das ist nicht nur ein Marketingversprechen, sondern technisch begründet: Die sparse MoE-Architektur aktiviert pro Inferenz nur 17 Milliarden von 397 Milliarden Parametern. Damit werden Rechenressourcen wesentlich effizienter genutzt als bei Dense-Modellen vergleichbarer Gesamtgröße.
Für Unternehmen bedeutet das: Spitzenleistung zu einem Bruchteil der bisherigen Betriebskosten. Insbesondere bei skalierenden Anwendungen – etwa in der Kundenbetreuung, im Dokumentenmanagement oder in der Softwareentwicklung – kann sich dieser Kostenvorteil erheblich auswirken.
In der Einordnung gegenüber etablierten Frontier-Modellen westlicher Anbieter bewegt sich Qwen3.5-Plus damit deutlich im unteren Bereich der typischen Preisspanne für vergleichbare Modelle. Wer bisher Flaggschiff-APIs von OpenAI oder Anthropic nutzt, zahlt dort in der Regel ein Vielfaches pro Million Token – insbesondere für erweiterte Reasoning- oder Langkontext-Fähigkeiten. Qwen3.5 bietet beides in einem Paket und positioniert sich damit nicht nur als technische, sondern auch als wirtschaftliche Alternative, vor allem für Anwendungen mit hohem Token-Durchsatz. Für Self-Hosting-Szenarien kommt hinzu, dass die Infrastrukturkosten bei 17 Milliarden aktiven Parametern deutlich näher an einem mittelgroßen Dense-Modell liegen als an einem 397-Milliarden-Parameter-Dense-Modell – was die GPU-Stunden-Kalkulation erheblich erleichtert.
Verfügbarkeit: Wo kann man Qwen3.5 nutzen?
Das Open-Weight-Modell Qwen3.5-397B-A17B ist unter der Apache-2.0-Lizenz frei verfügbar und kann über folgende Plattformen bezogen werden:
- Hugging Face – unter der Modell-ID
Qwen/Qwen3.5-397B-A17B - ModelScope – für Nutzer in China oder ohne stabilen HuggingFace-Zugang
- Qwen Chat – direkter Zugang über Web, Desktop und Mobilgerät
- Alibaba Cloud Model Studio – API-Zugang für Entwickler und Unternehmen, kompatibel mit OpenAI- und Anthropic-Spezifikationen
Weitere Modellgrößen der Qwen3.5-Familie sollen in den kommenden Wochen folgen – Alibaba hat angekündigt, dass die erste Veröffentlichung nur der Auftakt einer breiteren Modellreihe ist.
Einordnung: Qwen3.5 im Wettbewerb
Die Veröffentlichung von Qwen3.5 fällt in eine Phase intensiver Konkurrenz im chinesischen KI-Markt. ByteDance hatte mit Doubao 2.0 einen Tag vor dem Qwen3.5-Launch sein eigenes Modell-Update veröffentlicht – ein deutliches Signal für den beschleunigten Entwicklungszyklus chinesischer KI-Firmen. Wo früher Quartale zwischen großen Releases lagen, sind es heute Wochen.
Gegenüber westlichen Modellen positioniert sich Qwen3.5 explizit als Herausforderer. Alibaba vergleicht das Modell direkt mit GPT-5.2, Claude Opus 4.5 und Gemini 3 Pro – und vermeidet dabei auffälligerweise jeden Vergleich mit DeepSeek, das seit seiner viralen Verbreitung zu einem Maßstab in der Open-Source-KI-Welt geworden ist. Bemerkenswert ist, dass Alibaba in den offiziellen Vergleichen DeepSeek nicht erwähnt – obwohl dieses Modell in vielen Open-Source-Szenarien aktuell als Praxisreferenz gilt. Während DeepSeek vor allem über aggressive Effizienz und Community-Adoption punktet, setzt Qwen3.5 stärker auf native Multimodalität und Agentic-Fähigkeiten im Enterprise-Kontext.
Für die globale KI-Landschaft ist Qwen3.5 ein weiteres Indiz dafür, dass die Leistungslücke zwischen chinesischen Open-Source-Modellen und proprietären westlichen Systemen weiter schrumpft – mit potenziell erheblichen Auswirkungen auf die Infrastrukturwahl für KI-Anwendungen weltweit.
Qwen3.5 vs. DeepSeek vs. Llama 4.x – ein Meta-Vergleich
Wer heute eine Open-Weight-Strategie plant, hat de facto drei konkurrierende Modell-Familien auf dem Radar – und alle drei unterscheiden sich weniger in rohen Benchmark-Zahlen als in ihren strategischen Profilen:
| Kriterium | Qwen3.5-397B-A17B | DeepSeek-R2 / V3 | Llama 4.x (Meta) |
|---|---|---|---|
| Lizenz | Apache 2.0 (vollständig frei) | MIT / eigene Lizenz (kommerzielle Einschränkungen möglich) | Llama-Lizenz (Nutzungsbeschränkungen ab 700 Mio. MAU) |
| Architektur | Sparse MoE, nativ multimodal | MoE, text-fokussiert | Dense / MoE gemischt, multimodal |
| Hardware-Bedarf (Hosting) | ~8× H100 empfohlen (17B aktiv) | Vergleichbar, je nach Variante | Variiert stark je nach Modellgröße |
| Stärken | Agentic Tasks, Multilingual (201 Sprachen), GUI-Steuerung | Sehr starkes Reasoning, Coding, günstiger API-Preis | Ökosystem-Integration (Meta-Stack), breite Community |
| Typische Einsatzfelder | Enterprise-Automatisierung, multilinguale Anwendungen, visuelle Agenten | Forschung, Coding-Assistenten, preissensitive API-Nutzung | Consumer-Apps, interne Unternehmenstools mit Meta-Infrastruktur |
| Enterprise-Guardrails | Separates Qwen3Guard-Modell erforderlich | Eigene Safety-Layer vorhanden, aber begrenzt dokumentiert | Llama Guard als separates Safety-Modell |
Kurzgefasst: DeepSeek bleibt die erste Wahl für Teams, die maximale Reasoning-Tiefe oder niedrigste API-Kosten priorisieren. Llama 4.x punktet vor allem bei Unternehmen, die bereits im Meta-Ökosystem arbeiten oder eine sehr breite Community-Unterstützung benötigen. Qwen3.5 differenziert sich durch seine native Multimodalität, die deutlich breitere Sprachunterstützung und die visual-agentic Fähigkeiten – und ist damit besonders attraktiv für Automatisierungsprojekte, die über reine Texterzeugung hinausgehen.
Fazit: Ein starkes Argument für Open-Source-KI
Qwen3.5 ist mehr als ein technisches Update – es ist ein Statement. Mit nativem multimodalem Training, drastisch gesenkten Inferenzkosten, leistungsstarken Agentenfähigkeiten und freier Verfügbarkeit unter Apache 2.0 liefert Alibaba ein Modell, das für Entwickler und Unternehmen gleichermaßen interessant ist. Ob Qwen3.5 in der Praxis hält, was die Benchmark-Zahlen versprechen, werden unabhängige Tests in den kommenden Wochen zeigen.
Wer KI-Infrastruktur plant oder bereits auf Qwen-Modelle setzt, sollte die neue Serie genau im Blick behalten – zumal weitere Modellgrößen noch ausstehen. Der Startschuss für die Qwen3.5-Familie ist gefallen. Es bleibt spannend.
Quellen: Offizieller Qwen-Blog, GitHub Repository (QwenLM/Qwen3.5), Digital Applied, Analytics Vidhya, WinBuzzer