
Redaktionshinweis: Dieser Artikel wurde mit Künstlicher Intelligenz erstellt und redaktionell kuratiert. Quellenstand: 9. Juni 2026. Die Angaben zu Benchmarks, Safeguards, Verfügbarkeit und Datenspeicherung basieren primär auf Anthropics eigener Veröffentlichung und den begleitenden System- und Produktinformationen. Unabhängige Reproduktionen liegen zum Redaktionsschluss nur begrenzt vor.
⚡ In 30 Sekunden
- Claude Fable 5 ist ab sofort allgemein verfügbar und laut Anthropic das stärkste bisher regulär freigegebene Claude-Modell.
- Claude Mythos 5 basiert auf derselben Modellbasis, bleibt aber für ausgewählte Cyber-, Forschungs- und Infrastrukturpartner reserviert.
- Die neue Benchmark-Grafik zeigt einen klaren Leistungssprung gegenüber Claude Opus 4.8, GPT 5.5 und Gemini 3.1 Pro – besonders bei agentischem Coding, Wissensarbeit, Vision, Tool Use und Terminal-Aufgaben.
- Bei sensiblen Themen wie Cybersecurity, Biologie, Chemie oder Distillation leitet Fable 5 Anfragen automatisch auf Claude Opus 4.8 um.
- Für Fable 5, Mythos 5 und künftige Modelle auf ähnlichem Fähigkeitsniveau gilt für Geschäftskundentraffic eine verpflichtende 30-Tage-Datenspeicherung.
🧭 Executive Summary für Entscheider
- Nicht nur Modellqualität bewerten: Anthropic zeigt mit Fable 5 und Mythos 5 ein neues Betriebsmodell für Frontier-KI mit Zugriffsklassen, Sicherheitsumleitungen und Retention-Vorgaben.
- Die Benchmark-Führung ist real, aber nicht grenzenlos: Gerade die mit Stern markierten Bereiche zeigen, dass Schutzmechanismen die praktische Nutzbarkeit mitbestimmen.
- Der eigentliche Enterprise-Punkt ist Governance: Für DACH-Unternehmen werden künftig Datenpolitik, Freigabemodell und Auditierbarkeit fast so wichtig wie die Benchmark-Leistung selbst.
✅ Was Sie jetzt konkret tun sollten
- Pilot definieren: Fable 5 in 2 bis 3 realen Langläufer-Workflows testen, etwa Code-Migration, Dokumentanalyse und agentische Wissensarbeit.
- Fallbacks beobachten: Im Test gezielt messen, wann sensible Anfragen auf Opus 4.8 zurückfallen und wie stark sich das auf Qualität, Reproduzierbarkeit und Logging auswirkt.
- Retention prüfen: Die 30-Tage-Speicherung in AVV, DSFA, Datenschutzkonzept und interne Tool-Freigaben einordnen.
- Freigaben neu denken: Hochleistungsmodelle nicht mehr nur nach Modellnamen, sondern nach Zugriffsklasse, Sicherheitsarchitektur und Datenpolitik bewerten.
👥 Für wen ist dieser Artikel?
CIOs, CDOs, IT-Leitungen und Plattformteams: für die Einordnung von Frontier-Modellen unter realen Betriebsbedingungen. Datenschutz-, Legal- und Governance-Verantwortliche: für die Bewertung von Datenspeicherung, Freigaben und Auditierbarkeit. Security- und Engineering-Teams: für den praktischen Blick auf Fallbacks, Tool Use und agentisches Coding.
Anthropic hat mit Claude Fable 5 und Claude Mythos 5 zwei neue Modellvarianten vorgestellt, die laut Anbieter einen deutlichen Sprung gegenüber allen bisher öffentlich verfügbaren Claude-Versionen markieren. Für Unternehmen im DACH-Raum ist daran vor allem eines interessant: Anthropic bringt nicht nur ein stärkeres Modell, sondern ein neues Betriebsmodell für Hochleistungs-KI.
Fable 5 ist allgemein verfügbar, wird bei sensiblen Themen aber automatisch ausgebremst. Mythos 5 basiert auf derselben Modellbasis, bleibt jedoch einem kleinen Kreis vertrauenswürdiger Organisationen vorbehalten. Genau darin liegt die eigentliche Nachricht dieses Launches: Die Zukunft starker KI-Modelle wird nicht nur über Benchmark-Leistung entschieden, sondern über Sicherheitsarchitektur, Governance und Zugriffsmodelle.
Wer Anthropics Entwicklung seit Claude Mythos Preview verfolgt, erkennt hier eine klare Linie: Mehr Fähigkeit bedeutet nicht automatisch mehr offene Verfügbarkeit. Gleichzeitig verschiebt Anthropic die Messlatte gegenüber Claude Opus 4.7 und den späteren Opus-Updates sichtbar nach oben.
Die Benchmark-Grafik zeigt, worin Fable 5 und Mythos 5 wirklich vorne liegen
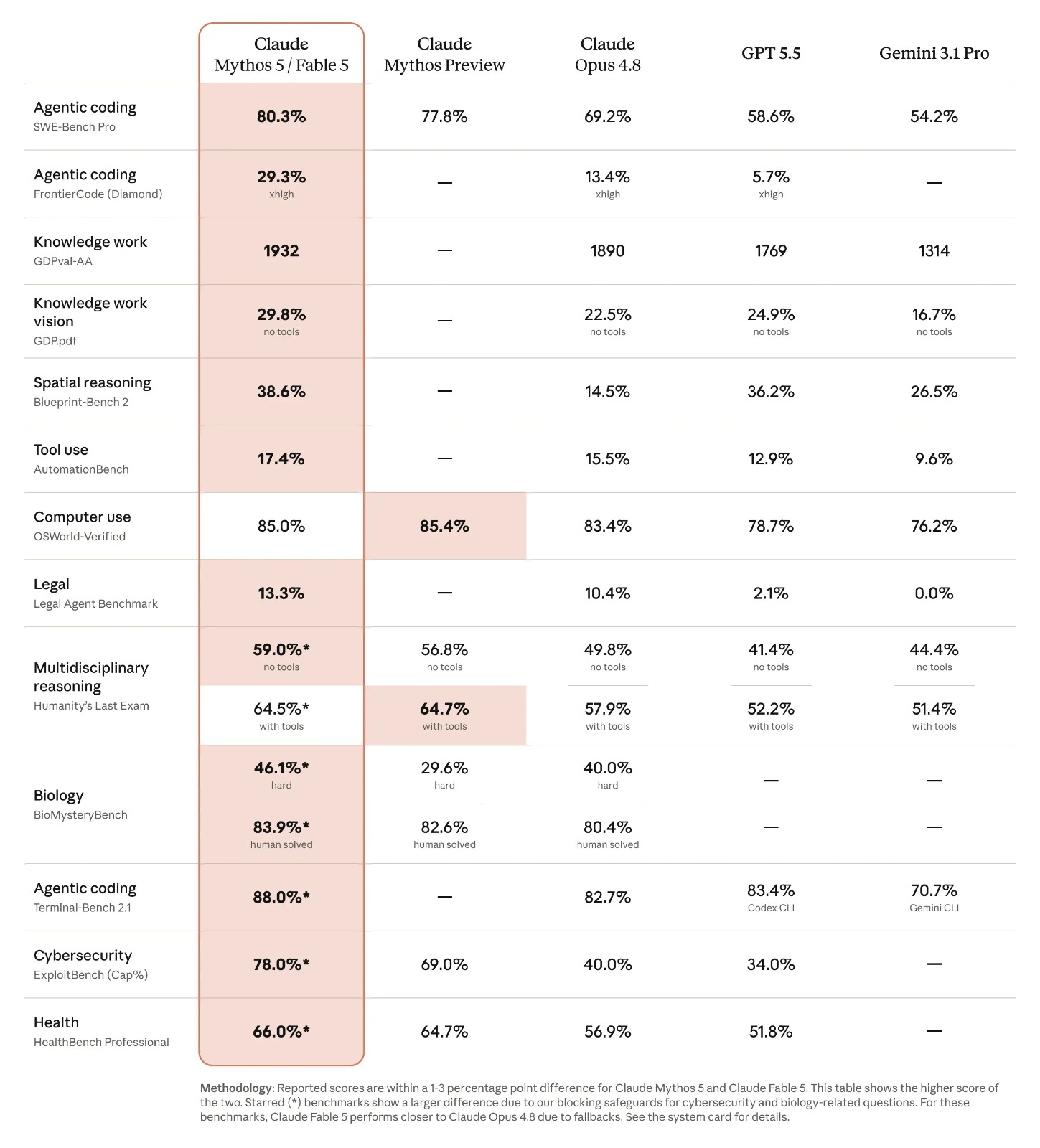
Die Grafik macht das Leistungsprofil sichtbarer als die bloße Produktankündigung. In mehreren für Unternehmen relevanten Disziplinen liegt die Mythos-5- beziehungsweise Fable-5-Modellbasis vor den öffentlich genannten Vergleichsmodellen. Besonders klar wird das bei agentischem Coding, Wissensarbeit, Vision, räumlichem Reasoning, Tool Use und Terminal-Aufgaben.
Die vier wichtigsten Benchmark-Signale für Entscheider
- SWE-Bench Pro: 80,3 % für Mythos 5 / Fable 5 gegenüber 69,2 % für Opus 4.8.
- FrontierCode (Diamond): 29,3 % gegenüber 13,4 % für Opus 4.8 – ein besonders deutlicher Abstand im High-End-Coding.
- OSWorld-Verified: 85,0 % – praktisch auf Mythos-Preview-Niveau und vor Opus 4.8 sowie GPT 5.5.
- Terminal-Bench 2.1: 88,0 % gegenüber 82,7 % für Opus 4.8 und 83,4 % für GPT 5.5 Codex CLI.
Was die Grafik konkret zeigt
- SWE-Bench Pro: 80,3 % für Claude Mythos 5 / Fable 5 gegenüber 69,2 % für Claude Opus 4.8, 58,6 % für GPT 5.5 und 54,2 % für Gemini 3.1 Pro.
- FrontierCode (Diamond): 29,3 % gegenüber 13,4 % für Opus 4.8 und 5,7 % für GPT 5.5.
- GDPval-AA: 1932 Punkte gegenüber 1890 für Opus 4.8, 1769 für GPT 5.5 und 1314 für Gemini 3.1 Pro.
- GDPpdf ohne Tools: 29,8 % gegenüber 22,5 % für Opus 4.8, 24,9 % für GPT 5.5 und 16,7 % für Gemini 3.1 Pro.
- Blueprint-Bench 2: 38,6 % gegenüber 14,5 % für Opus 4.8, 36,2 % für GPT 5.5 und 26,5 % für Gemini 3.1 Pro.
- AutomationBench: 17,4 % gegenüber 15,5 % für Opus 4.8, 12,9 % für GPT 5.5 und 9,6 % für Gemini 3.1 Pro.
- OSWorld-Verified: 85,0 % für Mythos 5 / Fable 5, knapp hinter 85,4 % für Claude Mythos Preview, aber vor 83,4 % für Opus 4.8 und 78,7 % für GPT 5.5.
- Legal Agent Benchmark: 13,3 % gegenüber 10,4 % für Opus 4.8, 2,1 % für GPT 5.5 und 0,0 % für Gemini 3.1 Pro.
- Humanity’s Last Exam: 59,0 % ohne Tools und 64,5 % mit Tools; damit vor Opus 4.8 mit 49,8 % beziehungsweise 57,9 %.
- Terminal-Bench 2.1: 88,0 % gegenüber 82,7 % für Opus 4.8, 83,4 % für GPT 5.5 Codex CLI und 70,7 % für Gemini CLI.
⚠️ Methodik-Hinweis zur Grafik
Laut Fußnote liegen die gemeldeten Werte von Claude Mythos 5 und Claude Fable 5 bei vielen Benchmarks nur innerhalb von 1 bis 3 Prozentpunkten auseinander. Die Tabelle zeigt jeweils den höheren der beiden Werte. Die mit Stern markierten Benchmarks weichen stärker ab, weil Sicherheitsbremsen bei Cybersecurity- und Biologie-bezogenen Fragen häufiger greifen. In diesen Bereichen soll Claude Fable 5 durch Fallbacks näher an Claude Opus 4.8 liegen.
Warum dieser Launch wichtiger ist als ein normales Modell-Upgrade
Auf den ersten Blick wirkt die Ankündigung wie ein klassischer Frontier-Release: bessere Benchmarks, mehr Autonomie, stärkere Coding- und Analysefähigkeiten sowie Fortschritte bei Vision, Memory und Life Sciences. Strategisch ist die Meldung aber größer.
Anthropic trennt erstmals sichtbar zwischen einem allgemein verfügbaren Modell mit eingebauten Schutzbremsen und einer eingeschränkt verfügbaren Hochrisiko-Variante mit gelockerten Sicherheitsgrenzen. Fable 5 und Mythos 5 beruhen laut Anbieter auf derselben Modellbasis. Der Unterschied liegt im Zugriff und in den Schutzmechanismen.
Für Unternehmen heißt das: Künftig ist nicht nur wichtig, welches Modell am stärksten ist. Entscheidend wird, unter welchen Sicherheits-, Daten- und Governance-Bedingungen ein Modell überhaupt genutzt werden darf.
Was Claude Fable 5 laut Anthropic besser kann
Anthropic beschreibt Fable 5 als neues State-of-the-Art-Modell für lange, komplexe und autonome Aufgaben. Besonders relevant für Unternehmen sind fünf Felder.
1. Softwareentwicklung
Anthropic verweist auf frühe Tests mit Stripe, bei denen Fable 5 in einer großen Ruby-Codebasis eine Migration in einem Tag erledigt haben soll, die sonst ein Team über zwei Monate beschäftigt hätte. Die neue Vergleichsgrafik stützt diesen Anspruch zumindest auf Benchmark-Ebene: 80,3 % auf SWE-Bench Pro und 29,3 % auf FrontierCode (Diamond) sind ein klarer Abstand zu Claude Opus 4.8, GPT 5.5 und Gemini 3.1 Pro.
2. Wissensarbeit
In dokumentenbasierter Wissensarbeit und analytischen Benchmarks zeigt die Grafik ebenfalls Vorsprung. 1932 Punkte auf GDPval-AA und 29,8 % auf GDPpdf ohne Tools deuten darauf hin, dass Fable 5 besonders bei langen, informationsdichten Wissensaufgaben zulegen soll.
3. Vision und räumliches Reasoning
Das Modell soll präzise Zahlen aus wissenschaftlichen Diagrammen auslesen und aus Screenshots Web-App-Code rekonstruieren können. Dass Anthropic in der Grafik 29,8 % auf GDPpdf und 38,6 % auf Blueprint-Bench 2 ausweist, unterstreicht, dass Vision und strukturierte Interpretation nicht nur Nebendisziplinen sind, sondern ein echter Leistungstreiber des Releases.
4. Tool Use und Computer Use
Bei AutomationBench liegt die Modellbasis mit 17,4 % vor Opus 4.8 mit 15,5 % und GPT 5.5 mit 12,9 %. Im Bereich Computer Use erreicht sie 85,0 % auf OSWorld-Verified. Das ist knapp unter Mythos Preview mit 85,4 %, aber vor Opus 4.8 und den öffentlich genannten Konkurrenzwerten.
5. Wissenschaftliche und sensible Domänen
Vor allem Mythos 5 soll in Molekularbiologie, Genomik und Protein-Design deutliche Fortschritte zeigen. Gleichzeitig zeigt gerade die Grafik, warum Anthropic hier Sicherheitsgrenzen einzieht: Biologie, Cybersecurity und Gesundheit gehören zu den Bereichen, in denen die Modellfähigkeit sehr hoch ist und Schutzmechanismen besonders relevant werden.
⚠️ Wichtige Einordnung
Fast alle Leistungsangaben stammen direkt von Anthropic oder von frühen Partnern. Für Entscheider heißt das: Die Signale sind stark, aber die operative Bewertung sollte nicht nur auf Hersteller-Benchmarks beruhen. Gerade bei agentischen Workflows, Vision-Aufgaben und sensiblen Domänen bleiben eigene Evaluierungen Pflicht.
Was Claude Mythos 5 von Fable 5 unterscheidet
Anthropic macht selbst klar: Mythos 5 ist nicht einfach ein „noch besseres“ öffentliches Modell. Es ist dieselbe Modellbasis wie Fable 5, aber mit in bestimmten Bereichen gelockerten Sicherheitsmechanismen.
Mythos 5 wird zunächst über Project Glasswing bereitgestellt, also in Zusammenarbeit mit US-Regierungsstellen sowie ausgewählten Cyberverteidigern und Infrastrukturpartnern. Später soll ein breiteres Trusted-Access-Programm folgen. Zusätzlich plant Anthropic ein eigenes Trusted-Access-Programm für Biologie-Anwendungen.
Damit setzt Anthropic die Linie aus dem früheren Mythos-Preview-Start fort: maximale Fähigkeit bleibt in kritischen Domänen zunächst an Vertrauensmodelle und Zugangsstufen gebunden.
🚨 Strategische Folge für Unternehmen
- Leistungsstarke Modelle in kritischen Domänen könnten künftig nicht mehr als Standardprodukt auf den freien Markt kommen, sondern über Zugangsstufen, Partnerprogramme und Vertrauensmodelle verteilt werden.
- Ein Teil der spannendsten KI-Fähigkeiten wird in den nächsten Jahren womöglich nicht automatisch für jedes Unternehmen sofort verfügbar sein – selbst dann nicht, wenn der Anbieter die Technik bereits beherrscht.
Die eigentliche Innovation: Sicherheitsklassifikatoren statt bloßer Sperren
Am interessantesten ist an der Ankündigung das neue Sicherheitskonzept. Wenn Fable 5 Anfragen erkennt, die mit Cybersicherheit, Biologie, Chemie oder Distillation zusammenhängen, beantwortet es diese nicht selbst. Stattdessen wird die Anfrage automatisch von Claude Opus 4.8 bearbeitet. Nutzer sollen über diesen Wechsel informiert werden.
Anthropic beschreibt das als Mittelweg: nicht pauschal alles zulassen, aber auch nicht alles hart verweigern. Für Unternehmen ist das hochrelevant, weil es zeigt, wie Anbieter künftig abgesicherte Hochleistungsmodelle bereitstellen könnten.
Laut Anthropic betreffen diese Fallbacks im Durchschnitt weniger als 5 Prozent der Sessions. Gerade in regulierten Umgebungen werfen sie aber wichtige Fragen auf.
Praxisbeispiel: Fable-zu-Opus-Fallback im DevSecOps-Workflow
Ein Team lässt Fable 5 automatisiert eine CI/CD-Pipeline härten und verdächtige Shell-Sequenzen bewerten. Sobald der Prompt in einen sicherheitskritischen Bereich kippt, kann der Lauf auf Opus 4.8 umgeleitet werden. Für den Betrieb heißt das: Logs, Audit-Trails, Testergebnisse und Freigaben sollten nicht nur den Workflow, sondern auch den tatsächlichen Modellpfad dokumentieren.
🚨 Governance-Fragen vor dem Rollout
- Wie transparent ist der Modellwechsel für Endnutzer?
- Wie reproduzierbar bleiben Ergebnisse, wenn einzelne Anfragen auf ein anderes Modell umgeleitet werden?
- Wie geht man in Freigabe- und Audit-Prozessen mit solchen Modellwechseln um?
- Wie häufig entstehen False Positives bei fachlich sensiblen, aber legitimen Business-Anfragen?
Neue Datenregel: 30 Tage Speicherung für Mythos-Klasse-Modelle
Noch wichtiger für Enterprise-Teams ist die neue Datenpolitik. Anthropic führt für Fable 5, Mythos 5 und zukünftige Modelle mit ähnlichem oder höherem Fähigkeitsniveau eine verpflichtende 30-Tage-Datenspeicherung für Geschäftskundentraffic ein – sowohl auf First-Party- als auch auf Third-Party-Oberflächen.
Das Unternehmen betont, diese Daten nicht für das Training neuer Claude-Modelle zu nutzen und sie nur für sicherheitsbezogene Zwecke zu verarbeiten. Zusätzlich sollen Zugriffe protokolliert und die Daten nach 30 Tagen in fast allen Fällen gelöscht werden.
Für DACH-Unternehmen ist das nicht nur eine Datenschutzfrage, sondern auch eine Architekturfrage: Wer bislang mit restriktiveren Löschfristen, engeren Freigaben oder besonders sensiblen Datentypen arbeitet, muss seine Einführungsvoraussetzungen neu prüfen. Inhaltlich knüpft das direkt an Themen an, die AI-Fabrik bereits bei Privacy Guardrails und im Lernpfad zu Datenschutz und KI-Recht behandelt hat.
Praxisbeispiel: typische DSFA-Frage zur 30-Tage-Speicherung
Ein Krankenhaus oder Finanzdienstleister will Fable 5 für Dokumentzusammenfassungen einsetzen. Schon vor dem Pilot stellt sich die DSFA-Frage, ob Patientendaten, Schadendaten oder Finanzunterlagen für 30 Tage in diesem Betriebsmodell verarbeitet werden dürfen – selbst dann, wenn die Inhalte nicht zum Training verwendet werden. Genau diese Abwägung kann in regulierten Branchen zum eigentlichen Go/No-Go-Punkt werden.
⛔ Warum das für DACH-Unternehmen zentral ist
Wer Fable 5 oder spätere Mythos-Klasse-Modelle in regulierten Umgebungen einsetzen will, muss die 30-Tage-Speicherung sauber in DSFA, AVV-Prüfung, internes Datenschutzkonzept und Tool-Freigabe einordnen. Für viele Unternehmen könnte genau das zum eigentlichen Rollout-Blocker werden – nicht die Modellqualität.
Preise und Verfügbarkeit
| Zugang | Preis / Status | Einordnung |
|---|---|---|
| Claude API | 10 US-Dollar pro Million Input-Tokens · 50 US-Dollar pro Million Output-Tokens | Fable 5 laut Ankündigung ab sofort verfügbar |
| Pro, Max, Team, sitzbasierte Enterprise-Pläne | zunächst bis 22. Juni 2026 ohne Aufpreis enthalten | ab 23. Juni Nutzung über Credits, bis genug Kapazität vorhanden ist |
| Claude Mythos 5 | kein allgemeiner Self-Service-Zugang | zunächst Glasswing-Partner, später Trusted Access |
Auch das ist strategisch relevant: Anthropic signalisiert hohe Nachfrage und knappe Kapazität. Für Unternehmen heißt das, dass Verfügbarkeit, Preis und Nutzungsmodell bei Spitzenmodellen zunehmend dynamisch werden können.
Was das für DACH-Unternehmen praktisch bedeutet
Für Entwicklerteams
Fable 5 ist vor allem als Produktivitätshebel spannend. Wenn sich die Coding-, Analyse- und Vision-Leistung im Alltag bestätigt, könnte das Modell besonders in komplexen Engineering-Workflows, Review-Prozessen, Datenanalyse und agentischen Assistenzszenarien attraktiv werden.
Für IT- und Plattformverantwortliche
Hier steht eine andere Frage im Vordergrund: Wie führt man ein Modell ein, das kontextabhängig auf ein anderes Modell zurückfällt und zugleich unter strengeren Datenregeln läuft?
Für Datenschutz, Legal und Governance
Vor allem die 30-Tage-Speicherung ist relevant. Wer bislang mit kürzeren Retention-Annahmen oder restriktiveren Datenschutzfreigaben gearbeitet hat, muss seine Bewertung aktualisieren.
Für Security-Teams
Der Launch zeigt vor allem eines: Frontier-Modelle nähern sich in Cyber- und Forschungsdomänen einem Niveau, bei dem Anbieter selbst die freie Nutzung nur noch eingeschränkt verantworten wollen. Das ist ein deutliches Signal für die Risikoklasse, in die solche Systeme intern eingeordnet werden sollten.
Kritische Einordnung: Was noch offen bleibt
So beeindruckend die Ankündigung klingt, einige Punkte bleiben offen.
Erstens beruhen viele Leistungsangaben auf Herstellerangaben, Partnerzitaten und firmennahen Benchmarks. Das ist bei Frontier-Launches üblich, ersetzt aber keine unabhängige Validierung.
Zweitens ist noch unklar, wie stark die Schutzmechanismen in realen Business-Szenarien stören. Gerade in technischen, medizinischen oder forschungsnahen Arbeitskontexten könnten konservative Filter zu Reibung führen.
Drittens schafft die Trennung zwischen Fable und Mythos zwar Sicherheit, aber auch neue Intransparenz. Unternehmen sehen nicht nur ein Modell, sondern ein System aus Modell, Filterung, Zugriffsklasse und Policy. Genau diese Schicht entscheidet künftig mit darüber, wie nutzbar ein Spitzenmodell im Alltag wirklich ist.
Was Unternehmen jetzt tun sollten
- Prüfen, ob die 30-Tage-Datenspeicherung mit internen Datenschutz- und Compliance-Vorgaben vereinbar ist.
- Fable 5 nicht nur auf Benchmarks, sondern in realen Langläufer-Workflows testen – etwa bei Code-Migrationen, Dokumentanalyse, Tabellen, Vision-Aufgaben und Agentenprozessen.
- Im Pilot bewusst beobachten, wann Fallbacks auf Opus 4.8 passieren und wie sich das auf Qualität, Reproduzierbarkeit und Nutzererwartungen auswirkt.
- Interne Freigabeprozesse für Hochleistungsmodelle nicht mehr nur an Modellnamen knüpfen, sondern an Datenpolitik, Zugriffsklasse und Sicherheitsarchitektur.
Jetzt Enterprise-KI-Updates mit Substanz erhalten
Der AI-Fabrik Newsletter ordnet neue Modelle, Agenten und Infrastruktur-News für CIOs, CDOs, IT-Leitungen und Plattformteams nicht nach Hype, sondern nach Governance, Stack-Fit und Unternehmensnutzen ein.
Sie bekommen kompakte Einordnung, klare Rollout-Signale und praktische Relevanz für DACH-Unternehmen.
Fazit
Claude Fable 5 ist aus Unternehmenssicht nicht einfach das nächste starke Modell von Anthropic. Es ist der Start eines neuen Produktmusters für Frontier-KI: maximale Leistung, aber nur mit Sicherheitsumleitung, Zugriffsstufen und härteren Datenregeln.
Die Benchmark-Grafik verstärkt genau diese Lesart. Sie zeigt einen realen Leistungssprung gegenüber Claude Opus 4.8, GPT 5.5 und Gemini 3.1 Pro – macht aber zugleich sichtbar, dass die praktische Nutzbarkeit bei heiklen Domänen durch Safeguards mitbestimmt wird.
Für DACH-Unternehmen wird damit nicht nur die Frage wichtiger, welches Modell am besten ist. Entscheidend ist, unter welchen Kontrollmechanismen Anbieter solche Fähigkeiten überhaupt freigeben.
FAQ
Was ist Claude Fable 5?
Claude Fable 5 ist laut Anthropic das bislang leistungsstärkste allgemein verfügbare Claude-Modell. Es basiert auf einer Mythos-Klasse-Modellbasis, wird aber mit zusätzlichen Sicherheitsmechanismen ausgeliefert.
Was ist der Unterschied zwischen Fable 5 und Mythos 5?
Beide Modelle basieren laut Anthropic auf demselben zugrunde liegenden Modell. Fable 5 ist für allgemeine Nutzung abgesichert, während Mythos 5 in bestimmten sensiblen Bereichen mit gelockerten Schutzmechanismen nur ausgewählten Partnern zugänglich ist.
Warum fällt Fable 5 bei manchen Anfragen auf Opus 4.8 zurück?
Anthropic nutzt Sicherheitsklassifikatoren, um potenziell riskante Anfragen zu erkennen. In Bereichen wie Cybersecurity, Biologie, Chemie oder Distillation wird die Antwort dann automatisch von Claude Opus 4.8 übernommen.
Warum ist die 30-Tage-Speicherung für Unternehmen so wichtig?
Weil sie direkte Auswirkungen auf Datenschutz-Folgenabschätzung, AVV-Prüfung, interne Freigaben und Governance-Prozesse hat. Für viele regulierte Unternehmen ist das ein zentraler Rollout-Faktor.
Was sagt die Benchmark-Grafik über Mythos 5 und Fable 5?
Sie zeigt, dass die gemeinsame Modellbasis in vielen Aufgabenklassen vor Claude Opus 4.8, GPT 5.5 und Gemini 3.1 Pro liegt. Gleichzeitig macht die Fußnote klar, dass Fable 5 und Mythos 5 nicht in allen sensiblen Benchmarks identisch abschneiden, weil Fable 5 dort stärker durch Schutzmechanismen begrenzt wird.
Ist Mythos 5 öffentlich verfügbar?
Nein. Mythos 5 ist zunächst nur für Glasswing-Partner und später für ausgewählte Trusted-Access-Programme vorgesehen.
Quellen
- Anthropic: Claude Fable 5 and Claude Mythos 5, 9. Juni 2026
- Anthropic: Angaben zu Safeguards, Trusted Access, Retention Policy, Pricing und Availability auf anthropic.com
- Anthropic: Vergleichsgrafik zu Claude Mythos 5 / Claude Fable 5, Claude Mythos Preview, Claude Opus 4.8, GPT 5.5 und Gemini 3.1 Pro
- AI-Fabrik: Claude Mythos Preview: Anthropics gefährlichste KI bleibt unter Verschluss
- AI-Fabrik: Claude Opus 4.7: Anthropics neues Flaggschiff ist da
- AI-Fabrik: Privacy Guardrails: Wie KI-Systeme Datenschutz automatisch durchsetzen







